Appearance
数据库三级模式-两级映像
三级模式层级:
- 内模式(Internal Schema):描述数据的物理存储结构与存取方式,直接关联存储设备上的数据文件。
- 概念模式(Conceptual Schema,简称"模式"):定义数据的逻辑结构与关系,体现为数据库中的基本表,是全局数据的抽象表示。
- 外模式(External Schema):呈现用户视角的数据组织形式,通过视图、部分表等机制实现,是概念模式的逻辑子集。
两级映像机制:
- 外模式-概念模式映像:建立外模式与概念模式间的映射关系。当概念模式结构变更(如表结构调整)时,仅需调整此映像即可保持外模式不变,实现逻辑数据独立性。
- 概念模式-内模式映像:定义概念模式与物理存储的映射规则。当存储结构变更(如文件组织方式修改)时,通过调整此映像可维持概念模式不变,实现物理数据独立性。
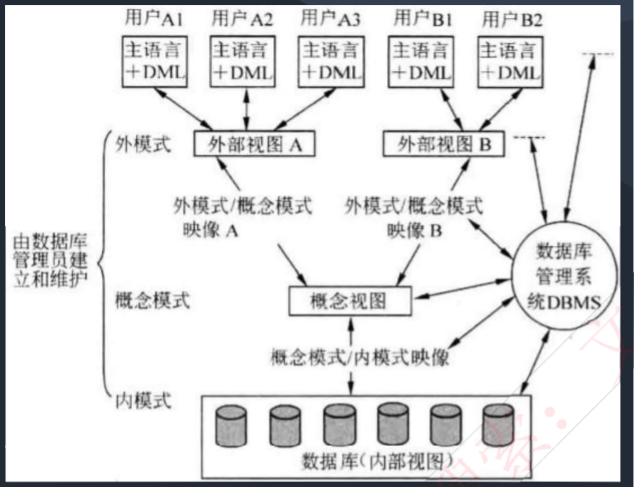
核心优势:两级映像机制有效隔离应用程序与底层数据,确保物理独立性(存储优化不影响应用逻辑)和逻辑独立性(数据结构演进不强制修改程序)。
关系数据库基本术语
键体系:
- 超键:能唯一标识此表的属性的组合。
- 候选键:超键中去掉冗余的属性,剩余的属性就是候选键。
- 主键:任选一个候选键,即可作为主键。
- 外键:其他表中的主键。
- 主属性:候选键内的属性为主属性,其他属性为非主属性。
完整性约束:
- 实体完整性约束:即主键约束,主键值不能为空,也不能重复。
- 参照完整性约束:即外键约束,外键必须是其他表中已经存在的主键的值,或者为空。
- 用户自定义完整性约束:自定义表达式约束,如设定年龄属性的值必须在 0 到 150 之间。
关系代数
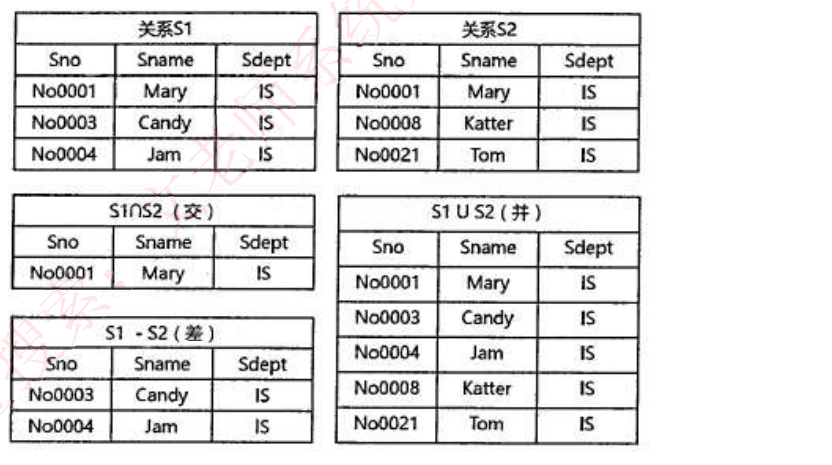
基本运算:
- 并(∪):两张表中所有记录数合并,相同记录只显示一次。
- 交(∩):两张表中相同的记录。
- 差(−):S1 − S2,结果是 S1 表中有而 S2 表中没有的那些记录。
- 笛卡尔积(×):S1 × S2,产生的结果包括 S1 和 S2 的所有属性列,S1 中每条记录依次和 S2 中所有记录组合,属性列 = S1+S2,记录数 = S1×S2。
投影(π)与选择(σ):
- 投影:按条件选择某关系模式中的某列(垂直分割),列也可以用数字表示。相当于 SQL 的
SELECT指定列。 - 选择:按条件选择某关系模式中的某条记录(水平分割)。相当于 SQL 的
WHERE条件。
口诀:投影选列,选择选行。
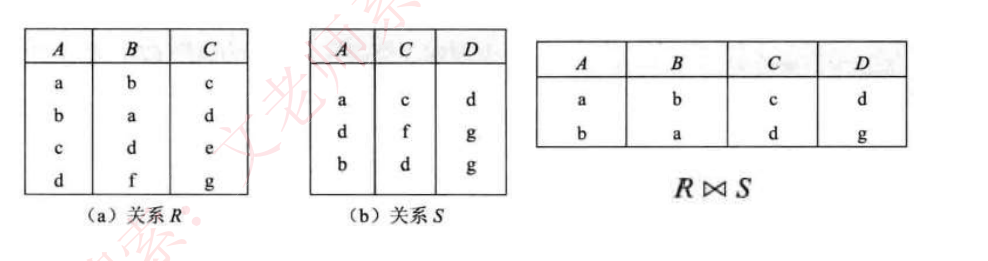
自然连接(⋈):
结果显示全部的属性列,但相同属性列只显示一次,显示两个关系模式中属性相同且值相同的记录。
关系代数表达式对应关系:
- 投影
π→ SQL SELECT 指定列 - 选择
σ→ SQL WHERE 条件 - 笛卡尔积
×→ FROM 多表(逗号分隔) - 自然连接
⋈→ 自动匹配同名列(去重列)
经典考题:自然连接
R ⋈ S与笛卡尔积R × S的等价转换
- 自然连接列数 = R列数 + S列数 − 相同列数
- 笛卡尔积列数 = R列数 + S列数
- 等价条件需要加上投影 π(去重列)和选择 σ(同名列值相等)
元组关系演算
- 定义:一种非过程化的查询语言,用于描述从数据库中检索哪些元组,而不指定如何检索。
- 表达式形式:
{ t | P(t) },其中t是元组变量,P(t)是一个谓词(条件)。 - 存在量词
∃:表示"存在",只要存在一个元组使条件成立,t就会被选中。 - 全称量词
∀:表示"所有"。 - 属性引用:通过位置(索引)引用,如
t[3]表示元组t的第三个属性。
解题技巧:遍历关系中每个元组,检查是否存在(
∃)或是否所有(∀)满足条件,按位置索引比较属性值。
函数依赖
基本概念:
给定一个 X,能唯一确定一个 Y,就称 X 函数确定 Y,或者说 Y 函数依赖于 X,记作 X → Y。
依赖分类:
| 类型 | 定义 | 示例 |
|---|---|---|
| 完全函数依赖 | X → Y,且 X 的任何真子集都不能确定 Y | (A,B) → C,A↛C,B↛C |
| 部分函数依赖 | X → Y,但 X 的真子集也能确定 Y | (A,B) → C,且 A → C |
| 传递函数依赖 | X → Y,Y → Z,且 Y↛X(X 和 Y 不等价) | A → B,B → C,B↛A |
Armstrong 公理系统:
- 自反律(Reflexivity):如果 Y ⊆ X ⊆ U,则 X → Y 成立(平凡依赖)。
- 增广律(Augmentation):如果 X → Y 成立,且 Z ⊆ U,则 XZ → YZ 成立。
- 传递律(Transitivity):如果 X → Y 和 Y → Z 成立,则 X → Z 成立。
推导规则:
- 合并规则:X → Y 且 X → Z ⇒ X → YZ
- 伪传递规则:X → Y 且 WY → Z ⇒ XW → Z
- 分解规则:X → Y 且 Z ⊆ Y ⇒ X → Z
找候选键技巧:找出从未在右边出现过的属性,必然是候选键之一,以该属性为基础,根据依赖集依次扩展,看能否遍历所有属性,将无法遍历的加入候选键中。
范式(1NF / 2NF / 3NF / BCNF)
第一范式(1NF): 关系中的每一个分量必须是一个不可分的数据项。即表中不允许有小表。
第二范式(2NF): 在 1NF 基础上,每一个非主属性完全函数依赖于任何一个候选码。即非主属性不能依赖复合主键中的某一个列(消除部分函数依赖)。
第三范式(3NF): 在 2NF 基础上,表中不存在非主属性对码的传递依赖。
BC 范式(BCNF): 在 3NF 基础上进一步消除主属性对于码的部分函数依赖和传递依赖。通俗地说:每一个依赖的左边决定因素都必然包含候选键。
范式递进关系:
1NF ⊃ 2NF ⊃ 3NF ⊃ BCNF每次升级解决上一级的问题:
- 1NF → 2NF:消除部分函数依赖
- 2NF → 3NF:消除传递函数依赖
- 3NF → BCNF:消除主属性对码的部分和传递依赖
实例演算:
学生表(学号,学生姓名,系编号,系名,系主任,课程号,成绩)
- 候选键:(学号, 课程号)
- 1NF 问题:不满足 2NF,因为学号不能完全确定课程号和成绩
- 分解到 2NF:学生(学号, 姓名, 系编号, 系名, 系主任) + 选课(学号, 课程号, 成绩)
- 2NF 问题:学生表中 学号→系编号→系主任,存在传递依赖
- 分解到 3NF:学生(学号, 姓名, 系编号) + 系(系编号, 系名, 系主任) + 选课(学号, 课程号, 成绩)
模式分解
目的:解决关系模式中存在的数据冗余、插入异常、删除异常和更新异常问题,通过投影运算将低范式转换为高范式关系集合。
保持函数依赖
定义:分解后的多个关系模式,保持原来的依赖集不变。注意要消除掉冗余依赖(如传递依赖)。
判断方法:
- 快速判断法(充分条件):如果 F 上的每一个函数依赖都在其分解后的某一个关系上成立(左右两边属性都在同一个分解模式中),则这个分解是保持依赖的。
- 闭包方法:当分解后的子关系模式不能直接包含某个函数依赖时,使用闭包计算验证。
无损分解
定义:将分解后的子关系进行自然连接后,能完全恢复出原关系的所有数据,没有任何信息丢失或产生多余的元组。
定理(二分解判定):将 R 分解为 {R1, R2} 是无损的充要条件是: R1 ∩ R2 → (R1 − R2) 或 R1 ∩ R2 → (R2 − R1) 在 F⁺ 中成立。
口诀:交决定差。
表格法(通用判定):
- 画表格:行是子模式 Rᵢ,列是所有属性
- 子模式中含有的属性填
✓,否则填× - 根据函数依赖修改表格:若依赖左边属性值相同,则右边属性也强制相同(优先将 × 改为 ✓)
- 若最终存在某一行全部为
✓,则为无损分解
经典结论:模式分解中,无损分解不一定保持函数依赖,保持函数依赖也不一定是无损的。两者需分别判断。
E-R 模型与概念结构设计
数据模型三要素:
- 数据结构:所研究的对象类型的集合
- 数据操作:对数据库中各种对象的实例允许执行的操作的集合
- 数据的约束条件:一组完整性规则的集合
E-R 图基本元素:
- 椭圆表示属性
- 长方形表示实体
- 菱形表示联系(连线两端填写联系类型)
联系类型:一对一(1:1)、一对多(1:N)、多对多(M:N)
弱实体与强实体:弱实体依赖于强实体的存在而存在(如"家长"依赖于"学生")。
E-R 模型 → 关系模型转换规则:
- 每个实体对应一个关系模式
- 1:1 联系:可放到任意一端实体中作为属性,或单独成为一个关系模式
- 1:N 联系:在 N 端加入 1 端实体的主键,或单独成为一个关系模式
- M:N 联系:必须作为一个单独的关系模式,主键是 M 和 N 端的联合主键
E-R 图集成三大冲突:
| 冲突类型 | 定义 | 示例 |
|---|---|---|
| 属性冲突 | 同一属性在不同局部图中定义不一致 | 类型冲突(整数 vs 字符串)、取值域冲突({男,女} vs {M,F}) |
| 命名冲突 | 同名异义或异名同义 | "单位"既指部门又指计量单位 |
| 结构冲突 | 同一对象被抽象为不同的模型成分 | 同一对象在一图中是实体,另一图中是属性 |
数据库设计步骤
| 阶段 | 内容 | 产出物 |
|---|---|---|
| 1. 需求分析 | 分析数据存储要求 | 数据流图、数据字典、需求说明书 |
| 2. 概念结构设计 | 设计 E-R 图(分 E-R 图→合并 E-R 图) | E-R 图 |
| 3. 逻辑结构设计 | E-R 图转换为关系模式 | 关系模式、完整性约束、用户视图 |
| 4. 物理设计 | 确定数据分布、存储结构和访问方式 | 物理存储方案 |
| 5. 数据库实施 | 建立数据库、编制与调试应用程序 | 可运行的数据库 |
| 6. 运行和维护 | 评价、调整与修改 | 持续维护 |
关键题点:逻辑结构设计阶段的依据来自需求分析阶段的产物(需求说明文档、数据字典、数据流图)。
SQL 语言基础
DDL(数据定义语言):
CREATE TABLE— 创建表ALTER TABLE— 修改表DROP TABLE— 删除表PRIMARY KEY()— 指定主键FOREIGN KEY()— 指定外键CREATE INDEX/CREATE VIEW— 创建索引/视图
DML(数据操作语言):
SELECT ... FROM ... WHERE— 查询INSERT INTO ... VALUES()— 插入DELETE FROM ... WHERE— 删除UPDATE ... SET ... WHERE— 修改
常用语法:
GROUP BY— 分组查询,HAVING附加分组条件ORDER BY— 排序(默认升序 ASC,降序 DESC)AS— 更名运算:SELECT sno AS "学号" FROM t1LIKE— 字符串匹配:%匹配多个字符,_匹配一个字符DISTINCT— 过滤重复,只保留一条UNION— 取或运算(去重合并)INTERSECT— 取与运算(交集)- 聚合函数:
MIN、AVG、MAX、COUNT、SUM